This chapter will cover the following topics
- Basics of the Storage system
- Storage service provided by AWS
- Object storage v/s block storage
- Introduction of S3(Simple Storage Service)
- S3 bucket restrictions and limitations
- Bucket access control
- Important properties of S3
- Enable and manage versioning on S3
- Manage logging on S3
- Object tagging
- S3 storage class(Standard,SI,RR,Glacier)
- Life cycle management in S3
- Static website hosting using S3
- Security features in S3
- Cross region replication
- Managing S3 components using CLI commands
Basics of storage systems
Computer data storage, often called storage or memory, is a technology consisting of computer components and recording media that are used to retain digital data.
In simple terms, storage services are the storage space that is used to store data temporary or permanent.

Storage services provided by AWS
Cloud storage is used to hold the information used by applications
AWS offers a complete range of cloud storage services to support both application and archival compliance requirements
Below are the storage services provided by AWS:
Amazon EBS – Persistent local storage for Amazon EC2
Amazon EFS – A file system to make data available to one or more EC2 instances
Amazon S3 – Scalable, durable platform to make data accessible from any Internet location
Amazon Glacier – Highly affordable long-term storage
AWS Storage gateway – A hybrid storage cloud augmenting your on-premises environment with Amazon cloud storage
Object storage V/s Block storage
Storage services are usually categorized based on how they work and how they are used.

Below are the three storage types:
- Block storage Not physically attached to server Can be accessed as local storage devices like HDD For creating a file system, you need to install OS and DB e.g: AWS EBS
2. File storage Centralized place to store files and folders Centrally managed by service provider e.g: AWS EFS
3. Object storage Data stored as object Each object has data, metadata and unique id e.g: AWS S3
Introduction to S3

- S3 is a global service of AWS cloud based object storage service
- It is paid but very cheap service
- It is generally used to store static content
- You can store any kind of data, with any extension of the object
- Object size should be from 0 bytes to 5 TB max per object
- Buckets are region specific. Objects are stored in bucket and bucket cannot be nested
- Soft limit of the bucket is: 100 buckets/account
- S3 object URL example: https://rajant.s3.amazonaws.com/books/aws.pdf
Creating a bucket:



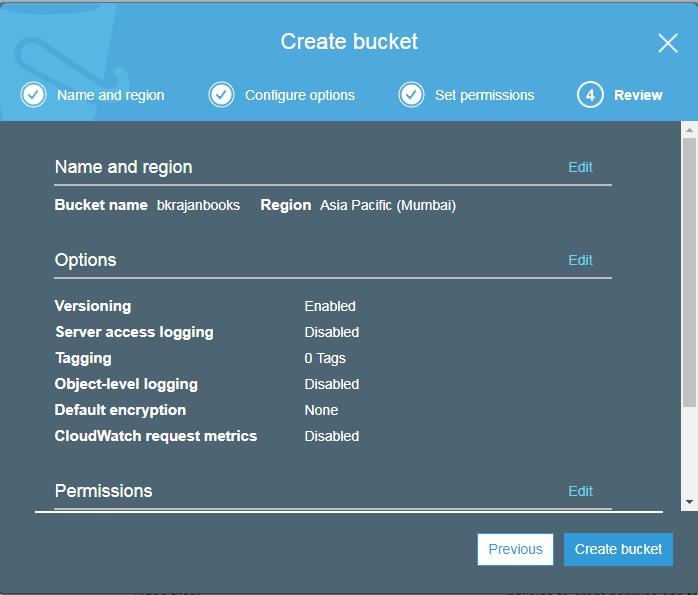
AWS S3 restrictions and limitations

- You can create bucket by using S3 console, API, and CLI
- S3 is a global service. It means you can store objects in a specific region but accessibility will be global.
- Soft limit of 100 buckets on AWS account
- Bucket ownership cannot be transferred
- Unlimited number of objects you can store
- Buckets cannot be nested
- Bucket name only contains lower case alphabets and limit is: from 3 to 63 characters
- By default, any object in the bucket is: private (Not accessible to others)
Bucket access control

By default, all objects in a bucket are: Private
After creating any object, the owner can grant permission to others using access control policy
There are two forms of giving permission:
- Resource based policy – Policy that applies on resource/bucket objects You can apply resource based policy in two ways:
i. Bucket policy
ii. Access Control List(ACL)
2. User policy – Policy that you associate with users
Resource based policy
- It is also known as bucket policy
- By using that ARN, we can allow or deny permission to that object
- Policy elements:
- Resource: Resource ARN to allow or deny permission
- Action: Any action on AWS resource
- Effect: This specifies allow or deny permission
- Principal: Account or user who allowed or denied
- Sid: Policy statement Id
User policy
- Associated with any user or group
- Unlike the bucket policy, no need to specify the principle.
- Once created, it can be attached to users/groups to grant them respective access.
Note:
Bucket will be deleted if it does not have any object.
Permission level will be different for buckets and its containing objects.
Important properties of S3
Following are important properties of S3
Transfer acceleration
This property of S3 is used when big amount of the data to be transferred between the on-premises environment and S3.
AWS uses cloud front edge locations – as they are spread across the globe which facilitates the transfer acceleration process.
- When to use?
- Data stored in centralized bucket and users are using the same bucket across the globe
- Regular data transfers GBs/TBs of data across continents
- Current bandwidth is not enough to handle multiple requests
Requester pay model
- Generally, you will be charged for data storage and data transfer
- You can configure your bucket as requester pay bucket
- The requester will pay for the requests they initiate to download or upload data into the bucket.
- You only have to pay for the data that you store in S3
- Once enabled, AWS won’t allow anonymous access of S3 objects
- If you initiate the requests using API, you need to include x-amz-request-payer in the header
Enable and manage versioning in S3
- Versioning can be enabled at the bucket level
- It allows creating multiple versions of the same file
- It protects from accidentals updates/deletion of objects
- Once you enable versioning, it displays hide and show toggle button at the bucket level
- When you delete an object, it adds delete marker instead
- There is no charge for using versioning property
- Versioning of the file does not dependent on the size of the file but depends on the timestamp
- Permission directly attached with an object so by enabling versioning, it will not be copied




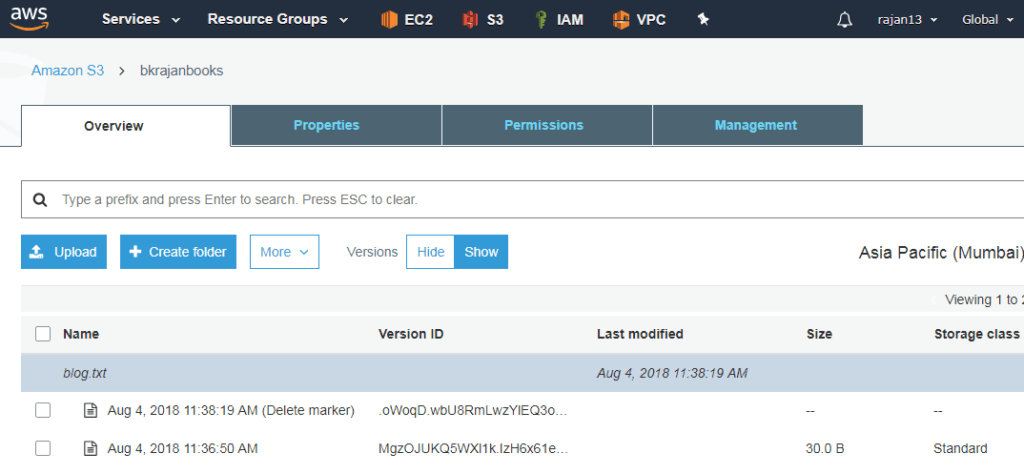
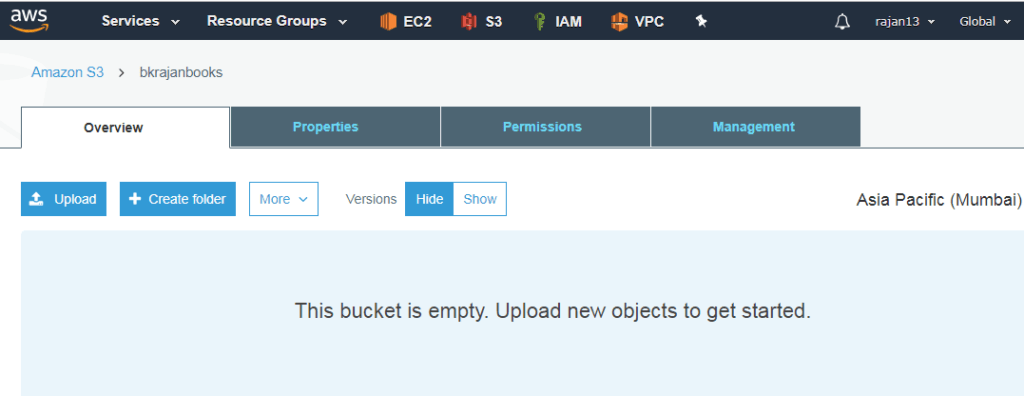
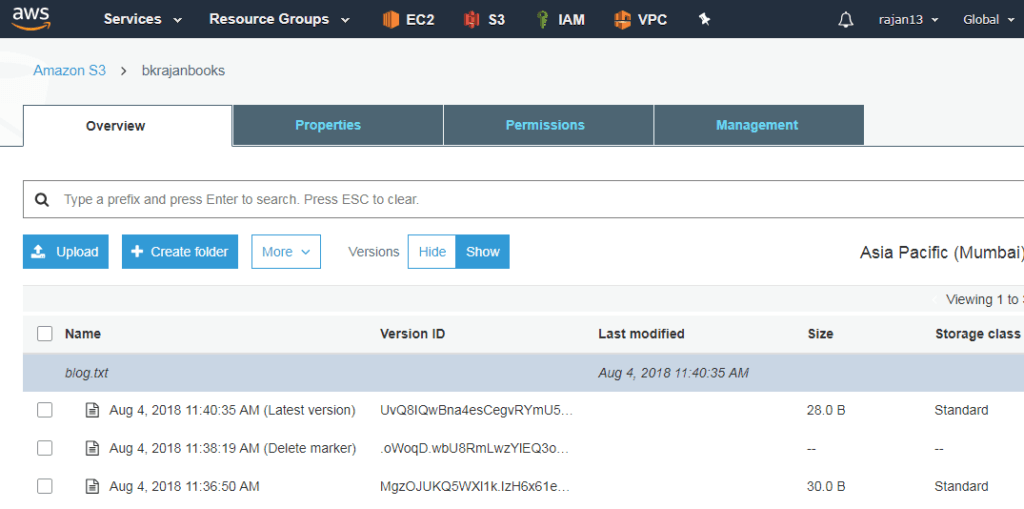

Manage logging in S3
- By logging, we can capture activities that happen at the bucket level.
- Logging is generally used for security and auditing purpose.
- The log can be captured in the same or another bucket but the source and destination bucket should be in the same region.
- By default, you will be able to access that logfile.
- Nobody will be able to edit or delete that log file except the owner.
- Logging can be enabled at the bucket level, not for any directory level.



Object Tagging
Tagging an object helps in categorizing the objects. S3 allows you to tag your objects
Each tag is a key value pair
For example :
If you are creating multiple objects in a bucket, let’s say testFile1.txt and testFile2.txt in customtestbucket. Now you want to process the same thing for both of the buckets
You can tag them as processed=yes if the processing is done for any of the buckets and set tag processed=false if that bucket yet to be processed
S3 storage classes

- Storage classes are nothing but different types of storage by which we can store objects based on different availability, durability, and cost
- Availability – When can I access my object after storing
- Durability – Will my object be available in the future when I needed
- Amazon S3 provides different types of storage classes for different storage needs
Storage classes can be divided into four classes based on how they are used
- S3 standard storage
- S3 standard Infrequent Access (IA) storage
- S3 Reduced Redundancy Storage (RRS)
- Glacier
S3 Standard Storage
- Used as general purpose storage for frequently accessed data
- Provides high availability, durability and high performance storage for frequently accessed data
- It can be used in
- content distribution, cloud applications, big data analytics, mobile or gaming applications, dynamic websites
- Key features:
- Low latency and high throughput
- 99.999999999%( 11 9s) durability
- 99.99% availability in a year
- Supports data lifecycle management for automatically migrating data from one class of storage to another
S3 IA storage
- It is used for the data that is less frequently used but needs to be available immediately when needed
- Provides high availability, low latency, and durable data storage
- It incurs relatively low per GB storage and retrieval costs
- It is best suited for backup, disaster recovery, and any long term storage needs
- Key features:
- Low latency and high throughput
- 99.999999999%( 11 9s) durability
- 99.99% availability in a year
- Supports data lifecycle management for automatically migrating data from one class of storage to another
S3 RRS
- Suitable for non-critical and reproducible data storage
- 99.99% durability
- 99.99% availability
S3 Glacier
- Very secure, low cost and durable data storage
- Ideal for storing long term data, backup archives and for disaster recovery
- Min storage duration – 90 days
- Provides 3 retrieval options:
- Expedite – 1 to 5 min – $$$
- Standard – 3 to 5 hours – $$
- Bulk – 5 to 12 hours – $
Life cycle management in S3
- It is a mechanism in S3 that enables you to either automatically transition an object from one storage class to another storage class or automatically delete an object
- You can achieve this based on the configuration that you can define rules for transition and deletion based on your requirement
- Why lifecycle?
- Auto cleaning
- Cost efficient
- Archival of data




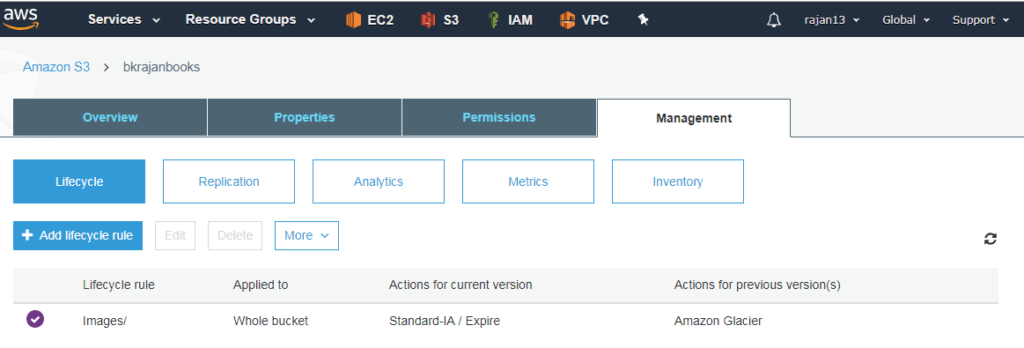
- To enable versioning is an optional step.
- If not enabled -> It will maintain the only current version
- If enabled -> It will maintain current and previous versions
- If you do not create any rule then no movement of objects will be there
- You are allowed to create multiple rules but no confliction should be there
- Standard -> Standard IF -> Glacier -> Expiry
- For the current version,
- ST -> ST IF -> By def. after 30 days, manually no time
- ST IF -> Glacier -> No wait day, no capping period
- Delete version -> Delete permanently (if no versioning enabled)
- Delete version -> Soft delete -> It will treat as the previous version
- For the previous version,
- Min. charge of 90 days
- If object deleted, deleted permanently
- Once lifecycle started, we can not disable versioning
- Once any file comes to the glacier, it will charge for 90 days
- So we should delete it after 150 days -> 30+30+90 = 150
Static website hosting using S3

- A static website can contain web pages with static content as well as client-side scripts
- S3 does not support server side scripting and due to that, you cannot host a site with any server side scripting such as PHP, JSP, ASP.Net
- You can host HTML pages, CSS, client-side scripts like JavaScripts, and so on



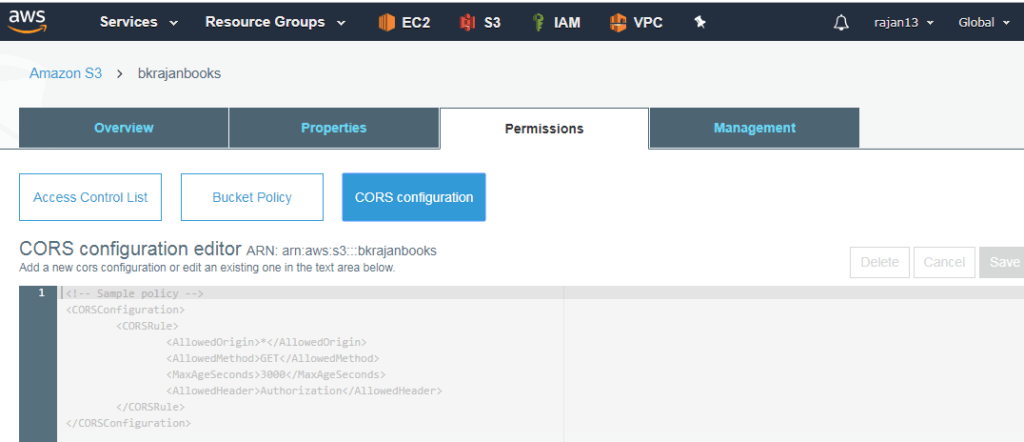
Cross Origin Resource Sharing(CORS)
CORS needs to be enabled when an application hosted on one domain wants to access the resource hosted on another domain
For ex: Web application and API hosted on different APIs
The static website from the bucket, loads font from a different domain
S3 -> Permissions -> CORS configuration
Security features in S3
Access control list (ACL)
We can mention the permission at the bucket and object level, who can access it.

Bucket Policy
You can mention who all can have access on bucket and in what ways.

Cross region replication
- Amazon S3 enables you to automatically and asynchronously copy objects from a bucket in one AWS region to another AWS region
- This bucket level feature can be configured in the source bucket
- In the replication configuration, you can specify the destination bucket where you want your source bucket objects to be replicated
- In the configuration, you can specify a key-name prefix.
- S3 replicates all the objects starting with the specific key prefixes to the destination bucket.
Pre-requisites
- Target and source bucket must be in a different region
- IAM role tagged to source bucket to replicate
- Both buckets should have version enabled
- Replicate to only one destination bucket
- Hard delete will not be replicated. Only add and update operations will be replicated
- Delete marker will be copied
- Any activity with life cycle cannot be copied
- Permission will not be copied
- Metadata will be replicated but tagging is not replicated
Hard delete will not be replicated. Only add and update operations will be replicated
Delete marker will be copied
Any activity with life cycle cannot be copied
Permission will not be copied
Metadata will be replicated but tagging is not replicated







Managing S3 components using CLI
Full S3 CLI commands list: https://docs.aws.amazon.com/cli/latest/reference/s3/index.html
Summary
As we have seen that S3 is one of the most favorite and important services in terms of exams as well as infrastructure perspective.
If you directly jump over to this chapter. Please find this link which is the complete tutorial series of AWS. We would recommend you to go through one by one and enjoy your learning journey with the Daily Code Buffer.
If you are free then join me in the next lecture that is: Notification services and Queueing services.


Pingback: AWS to sponsor the Rust programming language - Daily Code Buffer